오늘은 RNN 이전의 초기 Lanuage Model의 방식에 대해서 다룰 것이다.
Language Model?
Language Model이란 다음에 올 단어에 대한 예측을 의미한다.
문장이 주어지면 바로 다음 단어를 확률에 따라 예측하는 방식이다.
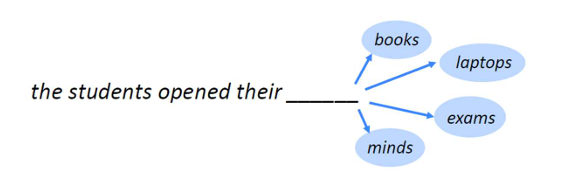
이걸 수학적 의미로 풀어보자면, 조건부 확률에 의해 x(1), x(2).. 뒤에 다음 단어 x(t+1)의 확률 분포를 계산하는 것으로, x(t)가 현재 시간의 단어라고 가정한다면, x(t+1)은 바로 다음 시간의 단어라고 볼 수 있다.
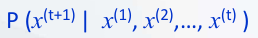
이 방식 자체를 Language Model이라고 할 수 있다.
(뒤에서 다룰 것이지만 모든 모델이 Language Model이라고는 볼 수 없다.)
n-gram Language Model
초기 Language Model은 count기반으로 우리가 가지고 있는 데이터베이스의 corpus안에 해당 단어와 문장이 얼마나 들어가있는지 개수를 세는 방식이다.
이 중 대표적인 예시가 n-gram 방식인데, unigram은 한 단어, bigram은 두 단어, 이렇게 연속적으로 나와있는 단어들이 얼마나 있는지 개수를 센 후, 다음 단어를 예측하는 방식이다.

방식은 아래와 같다. 조건부 확률이므로 분모에는 생성할 단어의 직전 문장, 그리고 우리가 생성할 단어 (여기는 예측하는 방식이다.)까지의 문장을 넣어준다.

그래서 정확히는 모델이 단어를 예측할 때, 다음 단어를 임의로 집어넣고 해당 단어까지 포함된 문장이 몇개 있는지를 세는 방식이다.
n-gram Language Model Example

4-gram Language Model을 구축한다면 다음과 같다.
문장이 엄청 나와있지만, 빈칸 앞에 있는 직전 3개의 단어만 보고, 이를 이용하여 다음 단어를 판정하는 방식이다. 즉, 4-gram이면 직전 3개 단어, 3-gram이면 직전 2개 단어를 보는 형태이다.
그리고 이 확률은 각각의 단어가 들어갈 확률은 계산할 수 없기 때문에 students opened their book이 들어있는 개수와, students open their가 들어있는 개수를 각각 count 한 후 확률로 만들어낸다.

count 기반의 Language Model 문제점
그렇다면 count 기반으로 다음 단어를 예측하는 Language Model의 문제는 뭘까?
아까도 이야기했듯이, 우리가 가지고 있는 데이터베이스 corpus (말뭉치)를 통해 확인하는 것이므로,
만약 그 문장이 데이터베이스 자체에 존재하지 않으면 계산이 되지 않는다. (Sparsity)
또한, 이 모든 n-gram의 count를 다 저장해야 되므로 용량 문제도 있을 수 있다. (Storage)

다음에는 본격적으로 RNN 기반의 모델들에 대해 다뤄볼 것이다.
📢 출처 : 동국대학교 인공지능학부 김지희 교수님 딥러닝 입문 수업, CS224N
'Machine Learning > 기초 개념' 카테고리의 다른 글
| [RNN] 단어 의미 모델링 (24) | 2024.11.20 |
|---|---|
| [머신 러닝] 가중치 (W), 편향 (Bias) (0) | 2024.08.14 |
| [머신 러닝] 퍼셉트론과 인공 신경망 (33) | 2024.08.12 |
| [머신 러닝] 선형 회귀 (0) | 2024.07.07 |
| [머신 러닝] 회귀와 분류 차이 (1) | 2024.07.05 |